4-1
对于一个神经元,并使用梯度下降优化参数,如果输入恒大于0,其收敛速度会比零均值化的输入更慢
假设这次采用sigmoid作为激活函数
由上式可知,当恒大于零时,梯度的符号仅与有关,所以,各个权重都会向同一个方向更新,造成z型更新的情况
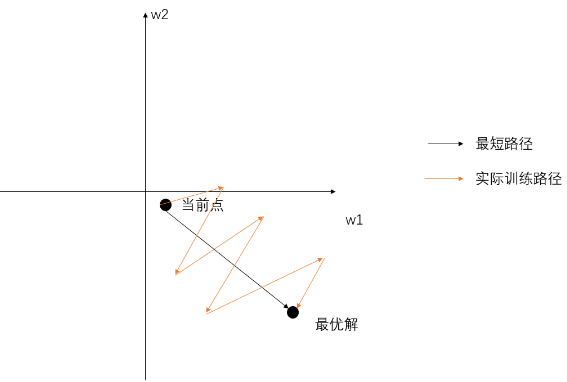
以只有两维的和做例子,因为和的梯度符号一致,要么都为正要么都为负,都为正时则往第一象限变化,都为负时则往第三象限变化,而如果此时最优解在第四象限,则实际训练路径会远远长于最短路径,就会使得网络收敛速度变慢。
所以为了避免Z型更新的情况,将输入进行零均值化,这样某次输入全部为正的可能性就很小,就会是正负掺杂的输入,每个的梯度符号和输入相关,也就不会全部都一样,也就不会Z型更新了。
4-2
试设计一个前馈神经网络来解决XOR问题,要求该前馈神经网络具有两个隐藏神经元和一个输出神经元,并使用ReLU作为激活函数
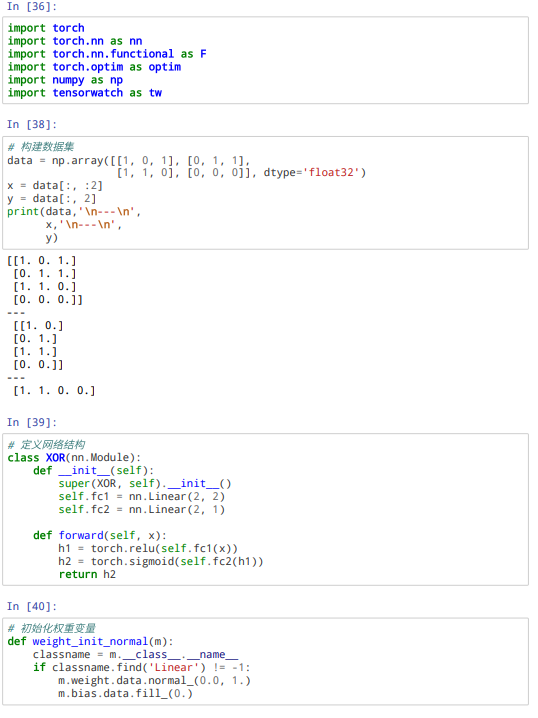
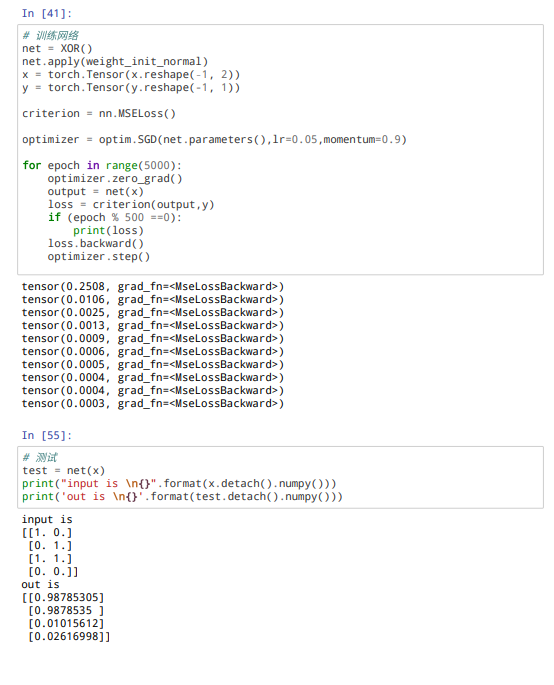
4-3
试举例说明“死亡ReLU问题”,并提出解决方法
举例:
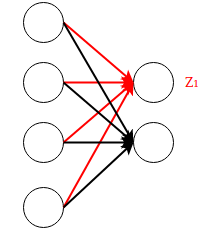
对上面的网络结构,是的矩阵,输入是的向量,第二层的激活函数为ReLU
如果由于上一次参数更新时,梯度过大,或者学习率设置太大,导致权重一下子更新过多。
就会导致
即激活函数的输出为0
在此次的梯度更新时:
而
也就是说,这几个参数将不再被更新了
解决方法:
- 把 ReLU换成LeakyReLU ,保证让激活函数在输入小于零的情况下也有非零的输出。
- 采用较小的学习率
- 采用 momentum based 优化算法,动态调整学习率
4-5
如果限制一个神经网络的总神经元数量(不考虑输入层)为N+1,输入层大小为,输出层大小为1,隐藏层的层数为,每个隐藏层的神经元数量为,试分析参数数量和隐藏层层数的关系。
4-7
为什么在神经网络模型的结构化风险函数中不对偏置进行正则化
其实也可以正则化偏置值,但是对于某一隐含层上的神经元来说,权重w是一个高维的参数矩阵,已经可以表达高方差问题,而偏置b仅仅是单个数字,对模型的复杂度影响不大,因此一般选择忽略不计
4-8
为什么在用反向传播算法进行参数学习时要采用随机参数初始化的方式而不是直接另?
因为如果参数都设为0,在第一遍前向计算的过程中所有的隐藏层神经元的激活值都相同。在反向传播时,所有权重更新也都相同,这样会导致隐藏层神经元没有区分性。这种现象称为对称权重现象。
引用自zhihu
4.9
梯度消失能否通过增加学习率来缓解
在一定程度上能够缓解,但易造成无法收敛等问题